
Anthropomorphism and the Crisis of Unregulated AI
Anthropomorphism and the Crisis of Unregulated AI
A Primer on AI, the Industries Misaligned Incentives and a Solution to the Crisis

1
Man made his gods, and furnished them
with his own body, voice, and garments.
2
If a horse or lion or a slow ox
had agile hands for paint and sculpture,
the horse would make his god a horse,
the ox would sculpt an ox.
3
Our gods have flat noses and black skins
say the Ethiopians. The Thracians say
our gods have red hair and hazel eyes.
- Xenophanes
Opening Remark:
The intersection of Hollywood and computer science is rare but met congenially in 2014 with the release of the Academy Award-winning film, The Imitation Game. In this film, Benedict Cumberbatch ditched Dr. Strange's magical 'Coat of Leviathan' and donned the white lab coat of the famous computer scientist Alan Turing. The Imitation Game focuses on how Turing decoded encrypted German intelligence communications for the British government in 1941. Just nine years later, in 1950, Turing would author his magnum opus, "Computing Machinery and Intelligence."
In the seven decades since Turing published his paper, the world has shifted its focus from hardware to software; the full mechanisms of capitalism now sit squarely on the ability of software to make our world more efficient and the pursuit of Artificial General Intelligence (AGI) has become the central scientific problem of the 21st century.
Intro & Framework:
Today's paper will achieve a few things. First, I'll provide a brief overview of the current state of Artificial Intelligence. This will involve the latest releases within the field, the industry's central actors, and what roles they play. Second, I'll introduce the business Anthropic.
In May of 2021 Anthropic was founded. Since May of last year, Anthropic (with only 41 employees) has gone through two funding rounds for $124M and $580M. They've raised an astonishing $704M in just 11 months (it is rare for a one-year-old startup to raise nearly ¾ of a billion dollars). To help contextualize Anthropics fundraising, I want to situate them within the broader AI ecosystem.
My thesis is that ethical AI needs to develop at a pace that is orders of magnitude higher than it currently is. In a private market, if technical ethicists and moral philosophers share the same incentives as AI product managers or software engineers, then ethical AI can progress at a similar rate as other 'exponential technologies.' I conclude that it makes sense for Anthropic to receive an influx of capital because Anthropic has the incentives of a for-profit business with the mission of an NGO. At scale, Anthropic will be a fundamental solution to the problem of incentive misalignment in the AI ecosystem.
Lastly, I want to acknowledge that there is no way for me to describe AI and its ecosystem succinctly that a pugnacious software engineer would not call ruinously reductive. I'm going to try either way. Additionally, there's a lot of industry terminology in this post. In reading this post, please optimize for the broader message of the text instead of getting caught in a web of technical minutiae. For some reason, AI is one of those industries where it's difficult to conduct an analysis that doesn't require a ton of industry verbiage. Let's begin.
The Remarkable State of AI:
From my understanding, the goal of the Artificial Intelligence community is to create Artificial General Intelligence (AGI). A secondary goal is to do it safely, ethically, and sustainably. The AI ecosystem is a behemoth. And AI is an exponential technology. Exponential technologies develop at or above the pace of Moore's Law.
A high-performance AI model generally follows a principle called Scaling Laws. Here are the drivers of scaling laws: "algorithmic innovation, data, and the amount of compute available for training."
These principles are formalized in the Scaling Hypothesis or the general industry consensus on Machine Learning:
"The strong scaling hypothesis is that, once we find a scalable architecture like self-attention or convolutions, which like the brain can be applied fairly uniformly (e.g. 'The Brain as a Universal Learning Machine' or Hawkins), we can simply train ever-larger Neural Networks and ever more sophisticated behavior will emerge naturally as the easiest way to optimize for all the tasks & data." Link.
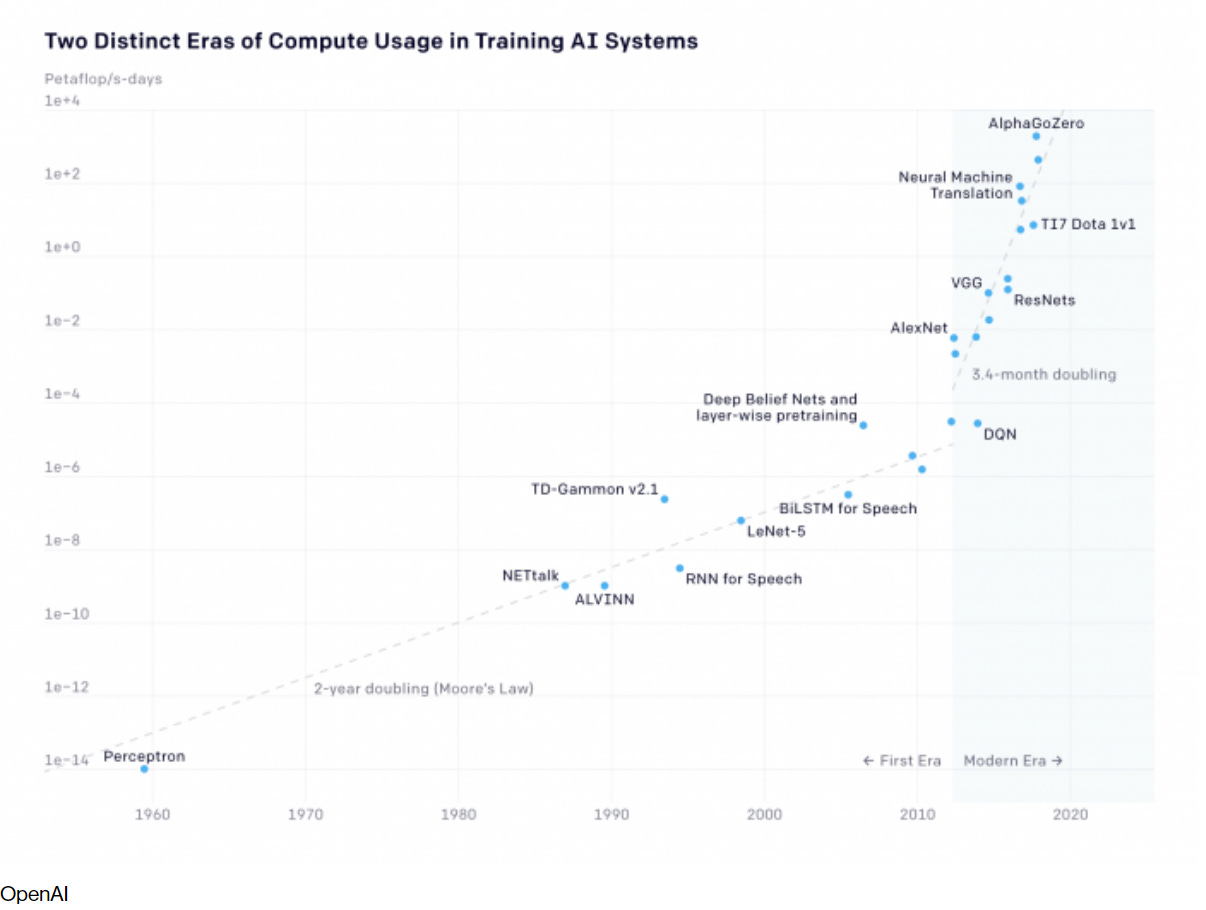
Let's double click on what makes AI exponential. AI development from 1959 to 2010 followed Moore's law; this means that the AI sector's computational power doubled every ~20 months. This era is known as the pre-deep learning era. From 2010 forward, computational power accelerated past Moore's law and has doubled every 4 to 9 months. The most sophisticated Machine Learning models have developed in conjunction with this trend.
Funding trends also reflect the breakneck pace of AI development, with a 100% increase in the funding amounts between 2020 and 2021. Between 2014 and 2019, funding increased at an average of 48%:

Furthermore, I want to highlight that there are several different types of Machine Learning Models that I'm not going to discuss in this post. However, let's examine the current standard for general-purpose, large generative ML models. Some of the most sophisticated Machine Learning models, are CLIP [55], Ernie 3.0 Titan [70], FLAN [71], Gopher [56], GPT-3 [11], HyperClova [43], Jurassic-1-Jumbo [46], Megatron Turing NLG [64], LaMDA [68], Pan Gu [78], and Yuan 1.0 [76], amongst others.
All of the models mentioned above are "pre-training models." For these, "the relationship between scale and model performance is often so predictable that it can be described in a lawful relationship — a scaling law." Link.
At the moment, large-scale generative pretraining models represent the frontier of Machine Learning, so in this post, I'll focus on them. "It is now the consensus of the AI community to adopt Pre-training Models (PTMs) as the backbone for downstream tasks rather than learning models from scratch." Link. These models allow engineers to design more effective architectures, utilize more rich contexts, improve computational efficiency, and conduct interpretation and theoretical analysis. The foremost Machine Learning Model is GPT-3.
GPT-3 is a Natural Language Processing or NLP model that can imitate writing from artists like Shakespeare or Edger Allen Poe with only a small input (this is possible through a feature called Few-shot learning). GPT -3's writing is often indistinguishable from human writing. Here is an article by GPT-3. GPT3 was released in 2020 and built with a stunning 175 billion parameters. GPT-2 was released in 2019 and had only 1.5 billion parameters, and in 2018 GPT-1 was released and had 117 million parameters. GPT-4 will likely be released at some point this or next year. Notably, Google recently announced a 1.6 trillion parameter model.
This is exponential development.
So far in this post, I've demonstrated Machine Learning's exponential development as a field. I've done this with evidence around a correlation between AI model performance and increases in parameters (in the case of GPT-3), computing power (via the chart from OpenAI), and funding trends. Machine Learning as a field is following an exponential trajectory. The third component of AI’s exponential course is data. Data is easily accessible from the internet, so there's less need to demonstrate how scraping the internet for data has to scale.
Scaling Laws have led to a hypothesis called the Scaling Hypothesis. The simplified Scaling hypothesis is that the pathway toward AGI has already been set. As long as the ML models follow their exponential trajectory, under scaling law assumptions, it is only a number of years until we'll see AGI.

Ilya Sutskever, the Chief Scientist at OpenAI, went viral after he tweeted this. It's not particularly relevant whether or not Sutskevers statement was true; what's relevant is the universal agreement that AI development is on a full-tilt trajectory towards AGI.
Every year, companies release larger AI models that have more outstanding capabilities. These models have played an increasingly prominent role in our lives and often without us being aware.
The Misaligned Actors Within AI:
The development of AI is the most interdisciplinary project in recorded history. Behind every software engineer is often a theoretical physicist, an analytical philosopher, a deontological ethicist, or an expert in semantic linguistics with a focus on embodied knowledge. These groups are often PhDs operating at the very extremities of their field. So what are the incentives for these actors? I believe it's some congruency of traits: an unfiltered intellectual curiosity, job security, an unhealthy paranoia for the future of our society, an obsessively competitive nature that borders on a personality disorder, and/or a firm belief that every person can live better, healthier, happier lives if we can successfully make AGI a reality.
The current cohort of public and private researchers and engineers have collectively put out over 120,000 papers on the Machine Learning research aggregator and social media tool, Paper With Code (PWC). This cohort is driving the exponential development of AI. Unfortunately, the incentive structure for these actors is not in the best interest of our future. In an ideal world, the AI ecosystem would have an equilibrium of safety and efficaciousness and operate as a virtuous flywheel:
Academia would agree on a set of frameworks, metrics, and safety testing methodologies. Legislators would bring about good new policies based on these recommendations from Academia. Private companies would construct products around these new policies. The technology would progress, and Academia would update its guidance. Updated laws. Updated products. Updated guidance. And so on and so forth.
In theory, the development of AI products would correspond to the development of safety mechanisms and enforcement techniques. The fundamental goal here is to maximize the upside of AI in terms of positive outcomes for the human condition and minimize the adverse externalities, such that it remains sensical for the development of AI to occur in the first place.
There has been some government intervention around safety, mostly around monitoring. For example, in 2020, in the US, there was the IOGAN ACT: Identifying Outputs of Generative Adversarial Networks Act. This act tasked the National Science Foundation to support research focused on studying the outputs of generative adversarial networks ( i.e., deepfakes) and similar technologies. However, the IOGAN Act is a far cry from an agreed-upon set of norms and rules for private actors. Most other government intervention has been focused predominantly on defense efforts.
We can split the cohort of AI actors into two groups. First, there are academics, NGOs, and non-profit organizations. Second, there are for-profit companies.
Group 1: Academics, NGOs, and Non-profit Organizations
Group one is comprised of academics, NGOs, and non-profits. This group has an expansive mandate. They act primarily as consequentialists as opposed to product-oriented enthusiasts. Here are the questions that drive Group 1, based on a conference held in 2019 at Stanford University:
How do we define AI?
What contributes to AI progress?
How do we use and improve bibliometric data to analyze AI and its impact on the world?
How can we measure the economic impact of AI, especially labor market dynamics and interaction with economic growth and well-being?
How can we measure the societal impact of AI, particularly on sustainable economic development, and the potential risks of AI to diversity, human rights, and security?
How can we measure the risks and threats of deployed AI systems?
Here are some key takeaways around AI safety that emerged from this conference.
There is no universally agreed-upon definition for AI to date. This prohibits KPIs and industry metric agreements.
Different sub-domains within the Machine Learning ecosystem, like NLP and Computer Vision, have separately demarcated metrics and definitions. This creates silos and complexity.
Platforms like arXiv and the PWC are repositories of progress in the AI ecosystem. There is no way to sift through the large volume of research autonomously or quickly delineate projects from pre-training methods, preprocessing, and post-processing.
There is a problem with the distribution of computational power between the public and private sectors.
There is a disclarity between the efficacy of parameter tuning vs. more intrusive model improvements.
AI in its current state will drive wealth inequality and polarization.
Better and safer AI requires better data, better testing, and better philosophical underpinnings.
For Group One, there is no $600,000 salary, supplemented by equity and bonuses that increase when a team releases a new product. Instead, the incentive structure for Group Ones' work is recognition from their peers and, more importantly, more positive societal outcomes for AI technologies.
Moreover, it cost $5M for OpenAi to train GPT-3 in 2020. According to the Center for Effective Altruism, "In 2016, more than 50 organizations had explicit AI Safety related programs, spending perhaps $6.6m."
According to the Anthropic team, "The largest language models that are free and publicly available are BigScience T0 (11B) [61], and Eleuther AI's GPT-J (6B) [69] and GPT-NeoX (20B) [45], which are one to two orders of magnitude smaller than those developed by industry. Although academics can easily access (at least some of) the larger models, it is typically only possible to do so through a (potentially expensive) company-controlled API. This is part of a broader and longer-running trend towards high-compute research migrating from Academia to industry that can be quantified (See Appendix A.7 for details )." Link.
Non-profits trying to create safety systems must meet the ML models in their latest states of development. However, the data I presented above demonstrates that oftentimes non-profit actors end up testing on older models that take less computational power because of the exorbitant costs. The consequence of this is that their insights on the risks of ML models may be outdated and not relevant to a potential legislator.
Group 2: The Corporations
Corporations are not strictly bad actors, and their research often enables and drives discoveries around more effective testing. The consummate players within the AI arena are large public companies (or well-funded private companies) who can afford the computing power necessary to conduct tests on the world's most prominent models (for example, it costs $5M to train OpenAI's GPT-3).
Sizable market demand for AI capabilities is a constant. Companies like Google, Apple, Facebook, and others can enhance their products and substantially increase revenues through the capabilities of Machine Learning models. Consider Google, its search ads business, Gmail, Youtube, Google maps, Google translate, Waymo (the self-driving unit), and Google assistant all rely on different types of Machine Learning models. Google saw over $250B in revenues in 2021. With revenues that large, even a fractional improvement in the performance of an ML model for a Google product may contribute to a $100M growth in revenue or improvement in margins.
Moreover, large companies can easily afford to train the world's most sophisticated ML models and can reward their developers handsomely for their work. As a result, today, product teams are incentivized to produce new products and bring them to market as soon as legally possible.
The Misalignment:
Here is the misalignment. Rewards go to well-funded actors who put out products, which in turn is driving exponential development. Meanwhile, poorly funded actors do not have the capacity or the incentive configuration to keep up with the exponential development of the AI sector. The implication here is that safety has been placed on the back burner. As consumers, we may be using products that simply do not align with our best interests but instead are geared to us monetarily contributing to the reward structures of for-profit actors.
The question or problem: How do we increase the training, testing, and review capabilities of Group 1 to meet the exponential pace of Group 2?
The Answer: We re-align Group 1's incentive structure to match the incentive structure of Group 2.
The Solution: Sell safety as a service. Anthropic fills the gap and re-aligns the incentive structure between (Group 1) safety and product releases (Group 2).
How Can Anthropic Contribute to the Ecosystem:
So far, this paper has focused on the pace of development in the ecosystem and the actors who participate in it. There is a substantial gap in the market for better safety research. Let's dive into how Anthropic fills the gap. Anthropic focuses on making reliable, interpretable, and steerable AI Systems; to do this, they develop techniques to train AI agents that are helpful, honest, and harmless.
Earlier in this paper, I spoke about GPT-3 and its current capabilities as a large generative model. Here are two samples of research that the Anthropic team has published that are relevant specifically to Pre-training Large Generative models like GPT-3:
A Mathematical Framework for Transformer Circuits
The Anthropic team’s paper ‘A Mathematical Framework for Transformer Circuits’ covers how "Even years after a large model is trained, both creators and users routinely discover model capabilities – including problematic behaviors – they were previously unaware of." To solve this problem, the Anthropic team reverse engineered the computations that transformer ML models conduct. This reverse engineering is called 'Mechanistic Interpretability.'
According to Nvidia's Rick Merritt, "A transformer model is a neural network that learns context and thus meaning by tracking relationships in sequential data like the words in this sentence.
Transformer models apply an evolving set of mathematical techniques, called attention or self-attention, to detect subtle ways [that] even distant data elements in a series influence and depend on each other."
Before Transformers, Deep Learning models were Recurrent Neural Networks (RNNs). With RNN’s for a Natural Language Processing Model, if an input is a sentence, the model needs to process the sentence in order, from the beginning to the end.
In 2017, however, the Google Brain team published the paper, Attention is All You Need. After this paper was published, Neural Network models became Transformer Models. These new models moved NLP and Computer Vision models closer to embodied knowledge through some highly sophisticated mathematical formulae. An externality of this progress was that Neural Networks became materially more challenging to interpret and analyze.
Transformer models are the cutting edge of AI development. This is evidence that Anthropic’s research is at the forefront of the capabilities of the field. This is an example of meeting the industry where it is instead of where it has been.
Anthropic is taking early steps to create safety at the vanguard of AI development. This is often not possible for more poorly funded not-for-profit research teams, and it's difficult for them to do so sustainably in the few cases it is possible.
Predictability and Suprise in Large Generative Models
Another example of the Anthropic team’s cutting edge research is their paper ‘Predictability and Suprise in Large Generative Models.’ This paper highlights how large-scale pre-training generative models (GPT-3, Megatron-Turing NLG, Gopher, etc.) follow scaling laws but also produce highly unpredictable outputs. In short, the larger the model, the more the surprise, even if that model is abiding by scaling laws.
The Anthropic team argues that large generative models often appear useful but in reality, often have 'socially harmful' behaviors due to their unpredictability.
To complement this paper the team also ran two experiments to demonstrate "how the combination of [predictable model loss but unpredictable outcomes] can lead to socially harmful behavior with examples from literature and real-world observations..."
Lastly, the team wrote this paper directly for policy-makers and academics interested in analyzing and critiquing large generative models.
Anthropics Positive Impact:
Whether or not a non-profit with much less funding would have been able to publish the two papers I just shared above is relatively unclear. What is clear is that the ability of a non-profit to reach insights like the ones above consistently and quickly over an extended period is unlikely, based on current funding trends. Anthropic is already a step ahead of non-profits who generally work on smaller, less relevant models due to their funding constraints. Anthropic is scaling safety research to meet the demands of exponential technology.
Anthropic does highly technical research with a lean team of 41, but they are hiring aggressively to help scale their efforts.
Anthropic is Public Benefit Corporation; as a result, its fiduciary responsibility is not its primary driver. Public benefit is its main driver. Anthropic won't spend its $702M on half-baked Neural Networks that are susceptible to spew neo-nazi nonsense. Anthropic is one of the only AI developers/researchers globally whose incentive structure serves the goals of a non-profit but will receive the rewards of a for-profit business, it is the perfect intermediary between the public and private sectors.
The Anthropic Team:
The entire Anthropic founding team used to work for OpenAI (the company that built GPT-3), which used to be a non-profit but became a for-profit company in 2019. The CEO, Dario Amodei, and President, Daniela Amodei, are siblings. Dario is a physicist who got his Ph.D. in Biophysics. Daniela was a policy guru and was a Congressional staffer for several years. At OpenAI, Daniela was the VP of Safety and Policy, and Dario was the VP of research.
Conclusion:
We've come a long way in this paper. I designed the circuitous journey of this post do a few things:
Explain the current state of AI and show its current trajectory.
Show who is currently building that future, and discuss how this collective of actors is misaligned to release products that benefit our societies.
Present Anthropic as a case study on how to re-align the incentives of AI actors and mitigate the worst harms of an impending AGI.
In the words of Google CEO Sundar Pichai, "the central struggle of every technology is harnessing it so that it benefits society… there has to be thoughtful regulation around AI." However, as with all sectors, Congressional staffers are not domain specialists; they rely heavily on experts to act as the moral compasses of our legislation. Unfortunately, market demand has sidelined non-profit researchers, and these researchers are struggling to meet the needs of the industry. As long as Anthropic is able to meet Artificial Intelligence where it is and not where it has been, then the private market should continue to fund them without restraint.
I believe that AI will change the world. It will eliminate cancer and cure Alzheimer's; it will drive our cars, safeguard our financial markets, educate our youth, and bring dignity to the elderly; it will design for our architects; it will develop software for our engineers and paint paintings for our artists. AI is an old testament phenomenon.
Let's make sure that if AI makes all the good things better, they don't make all the bad things worse. As Xenophanes first noted when he observed how ancient communities anthropomorphized their gods, "Our gods have flat noses, and black skins say the Ethiopians. The Thracians say our gods have red hair and hazel eyes."